Two modifications to the vanilla StorSeismic model, a Transformer-based network for made for various seismic processing tasks, are tested: a learnable positional encoding and low-rank attention matrices, resulting in a more efficient and effective network.
The integration of the proposed network into a conventional seismic processing workflow, particularly for marine seismic data, from denoising to obtaining post-stack data is demonstrated.
The comparison between the vanilla and the new architecture on realistic Marmousi and field data located in offshore Australia shows improvements on pretraining time, trainable parameters, and prediction results.
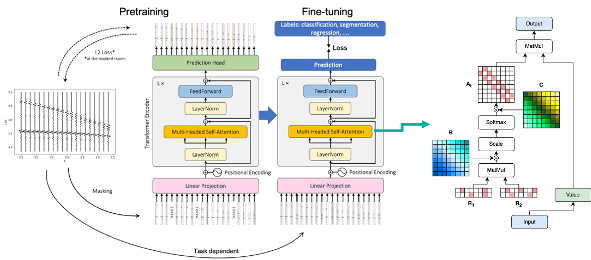
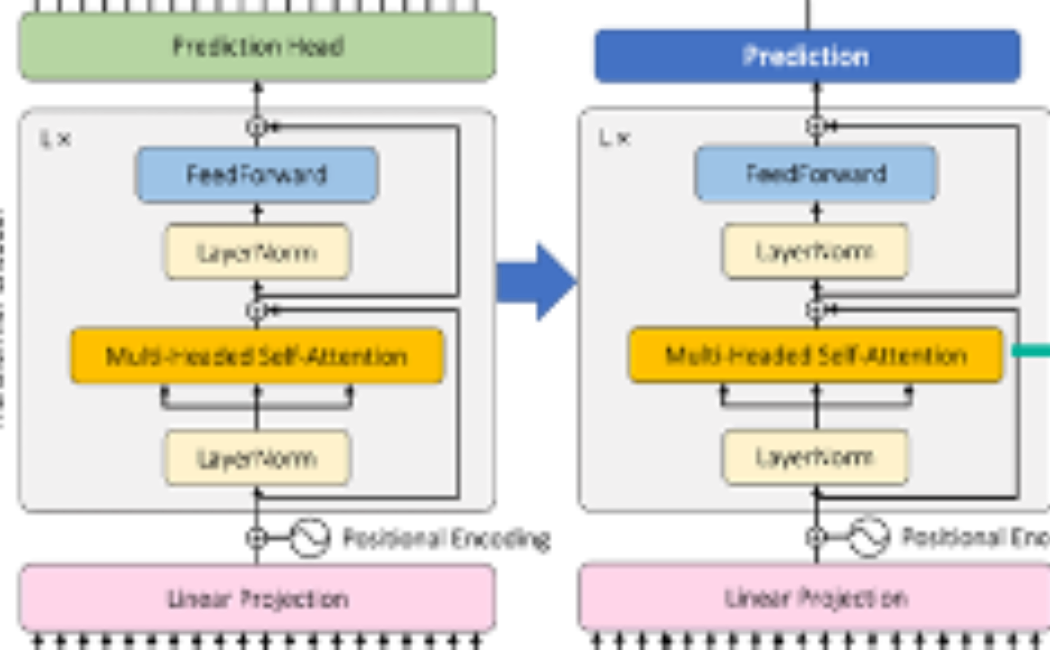
Figure 1. StorSeismic architecture and training steps. The square black box depicts the modified attention block which contains a low-rank attention and a learnable positional encoding.
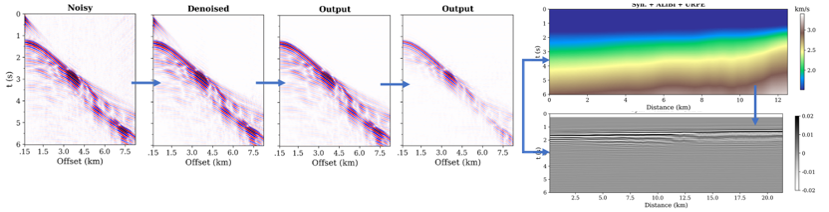
Figure 2. Seismic processing sequence performed by using the fine-tuned StorSeismic models: denoising, direct arrival removal, demultiple, and NMO correction.
Leave a Reply
Your email address will not be published. Required fields are marked *